
Comment fonctionnent les bases de données ? #
Les bases de données fonctionnent à l’aide d’un Système de Gestion de Base de Données (SGBD), qui fournit des outils pour le stockage, la récupération et la manipulation des données.
Tables #
Une table est une structure de données utilisée pour stocker des informations sous un format structuré (lignes et colonnes).
Chaque ligne représente une entité de données, et chaque colonne définit un champ d’information spécifique. Les données contenues dans ces tables peuvent être consultées, modifiées, mises à jour et organisées via le langage SQL.
Chaque colonne possède un nom, un type de données et un ensemble de contraintes qui définissent les valeurs autorisées.
Clés #
Les clés sont l’un des éléments les plus importants d’une base de données relationnelle pour maintenir la relation entre les tables et elles permettent également d’identifier de manière unique les données d’une table. La clé primaire est une clé qui permet d’identifier de manière unique le tuple de la base de données. En revanche, la clé étrangère est une clé utilisée pour déterminer la relation entre les tables par le biais de la clé primaire d’une table, c’est-à-dire que la clé primaire d’une table agit comme une clé étrangère pour une autre table.
Qu’est-ce qu’une clé primaire ? #
La clé primaire est une clé qui permet d’identifier de manière unique le tuple de la base de données. Une clé primaire est utilisée pour s’assurer que les données d’une colonne spécifique sont uniques. Une colonne ne peut pas avoir de valeurs NULL. Il s’agit soit d’une colonne de table existante, soit d’une colonne spécifiquement générée par la base de données selon une séquence définie.
La clé primaire d’une table est facultative, mais il est déconseillé de l’omettre.
Qu’est-ce qu’une clé étrangère ? #
Une clé étrangère est une colonne ou un groupe de colonnes dans une table de base de données relationnelle qui fournit un lien entre les données de deux tables. Il s’agit d’une colonne (ou de plusieurs colonnes) qui fait référence à une colonne (le plus souvent la clé primaire) d’une autre table.
Schémas #
Un schéma est une structure logique qui définit la manière dont les données sont organisées (tables, relations, contraintes, index, etc.).
Une base de données peut contenir plusieurs schémas.
CREATE SCHEMA entreprise;
CREATE TABLE entreprise.employes (
id INT PRIMARY KEY,
nom VARCHAR(100),
poste VARCHAR(50)
);
Contraintes #
Une contrainte est une règle qui définit les valeurs et les types de données autorisés pour une table ou une colonne. Les contraintes sont utilisées pour garantir l’intégrité et la cohérence des données dans une base de données. En cas de violation entre la contrainte et l’action sur les données, l’action est interrompue.
Les contraintes suivantes sont couramment utilisées en SQL :
NOT NULL- Garantit qu’une colonne ne peut pas avoir une valeur NULLUNIQUE- Assure que toutes les valeurs d’une colonne sont différentes.PRIMARY KEY- Une combinaison de NOT NULL et UNIQUE. Identifie de manière unique chaque ligne d’une table.FOREIGN KEY- Empêche les actions qui détruiraient les liens entre les tables.CHECK- Assure que les valeurs d’une colonne satisfont à une condition spécifiqueDEFAULT- Définit une valeur par défaut pour une colonne si aucune valeur n’est spécifiée.CREATE INDEX- Utilisé pour créer et récupérer très rapidement des données dans la base de données.
Index #
Un index est une structure de données qui améliore la vitesse des opérations de récupération des données en fournissant des chemins d’accès rapides.
Un index peut être créé sur une ou plusieurs colonnes d’une table.
CREATE INDEX idx_employes_nom ON entreprise.employes (nom);
La création d’un index occupe de l’espace mémoire dans la base de données et, comme il est mis à jour à chaque modification de la table à laquelle il est rattaché, peut augmenter le temps de traitement du SGBDR lors de la saisie des données. Par conséquent, la création d’un index doit être justifiée et les colonnes auxquelles il se rapporte doivent être soigneusement choisies (de manière à minimiser les duplications). Ainsi, certains SGBDR créent automatiquement un index lorsqu’une clé primaire est définie.
Vues #
Une vue est une table virtuelle basée sur le résultat d’une requête. Elle permet de simplifier les requêtes complexes et de fournir une vue simplifiée des données.
CREATE VIEW v_employes AS
SELECT e.id, e.nom, e.poste
FROM entreprise.employes e;
Transactions #
Garantir l’intégrité des données grâce aux propriétés ACID (atomicité, cohérence, isolation, durabilité).
Atomicité #
L’atomicité est le principe du tout ou rien. Lorsqu’une transaction est initiée, elle doit se terminer complètement ou ne pas se terminer du tout. Si une partie de la transaction échoue, la transaction entière échoue, la transaction entière est annulée, laissant la base de données inchangée. Par exemple, si vous transférez de l’argent entre des comptes bancaires, les opérations de débit et de crédit doivent réussir ensemble. Si l’une des parties échoue, aucune des deux opérations n’est appliquée, ce qui garantit que la base de données reste dans son état d’origine.
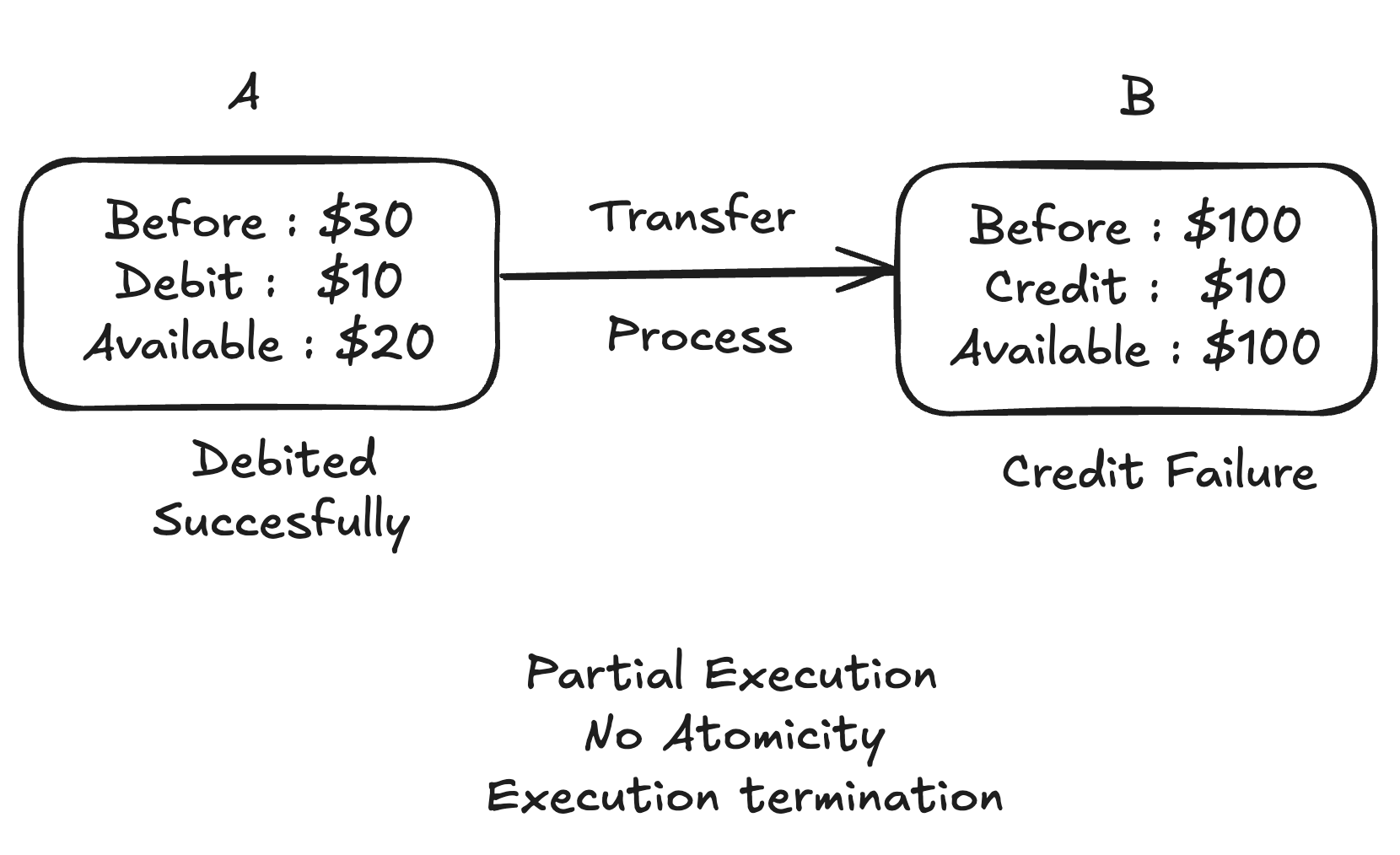
Cohérence #
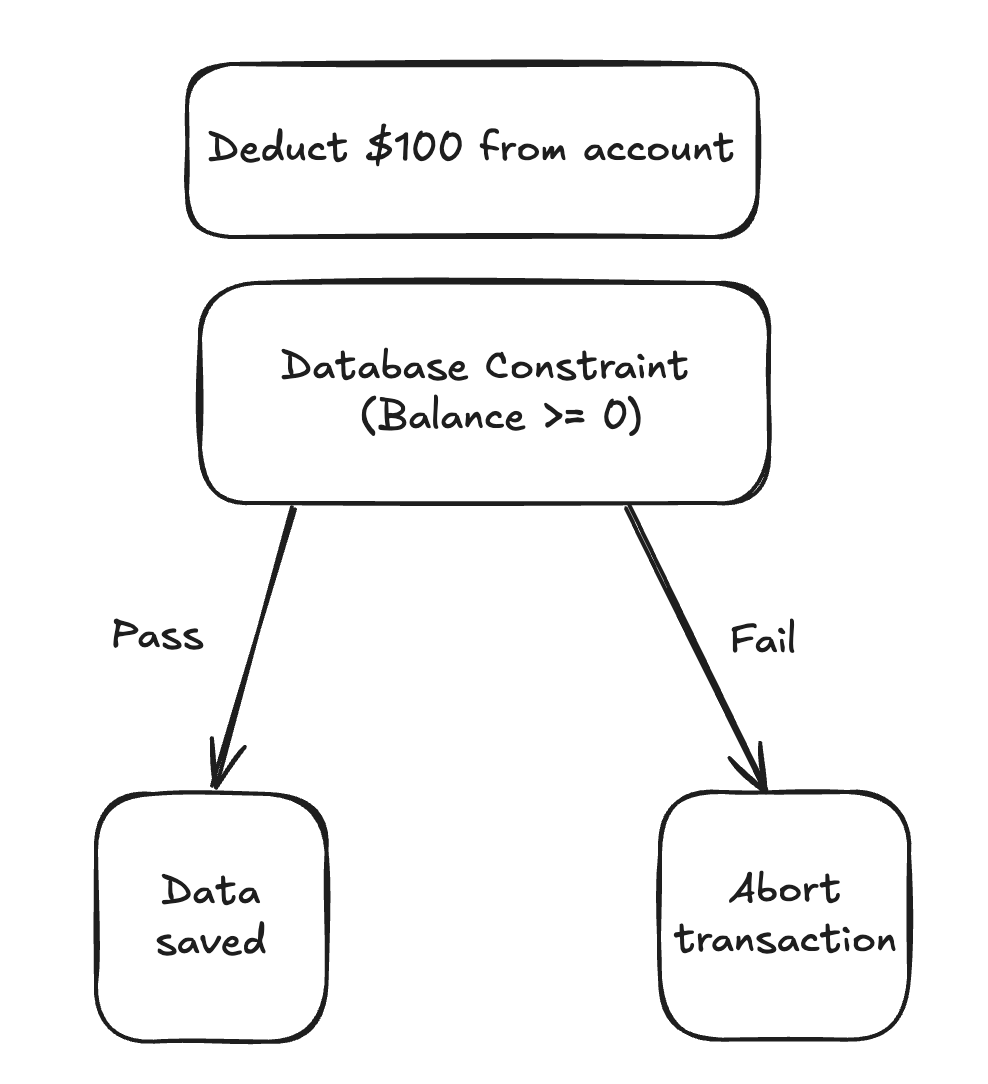
La cohérence garantit que la base de données reste dans un état valide avant et après la transaction. Cela signifie que toutes les contraintes d’intégrité des données sont maintenues tout au long de la transaction. Si une transaction enfreint une règle d’intégrité, elle ne sera pas validée. Par exemple, si vous avez une règle qui empêche les soldes négatifs sur les comptes bancaires, toute transaction tentant de mettre un compte à découvert sera annulée. Cela garantit que toutes les transactions conduisent la base de données d’un état cohérent à un autre, préservant ainsi l’exactitude des données.
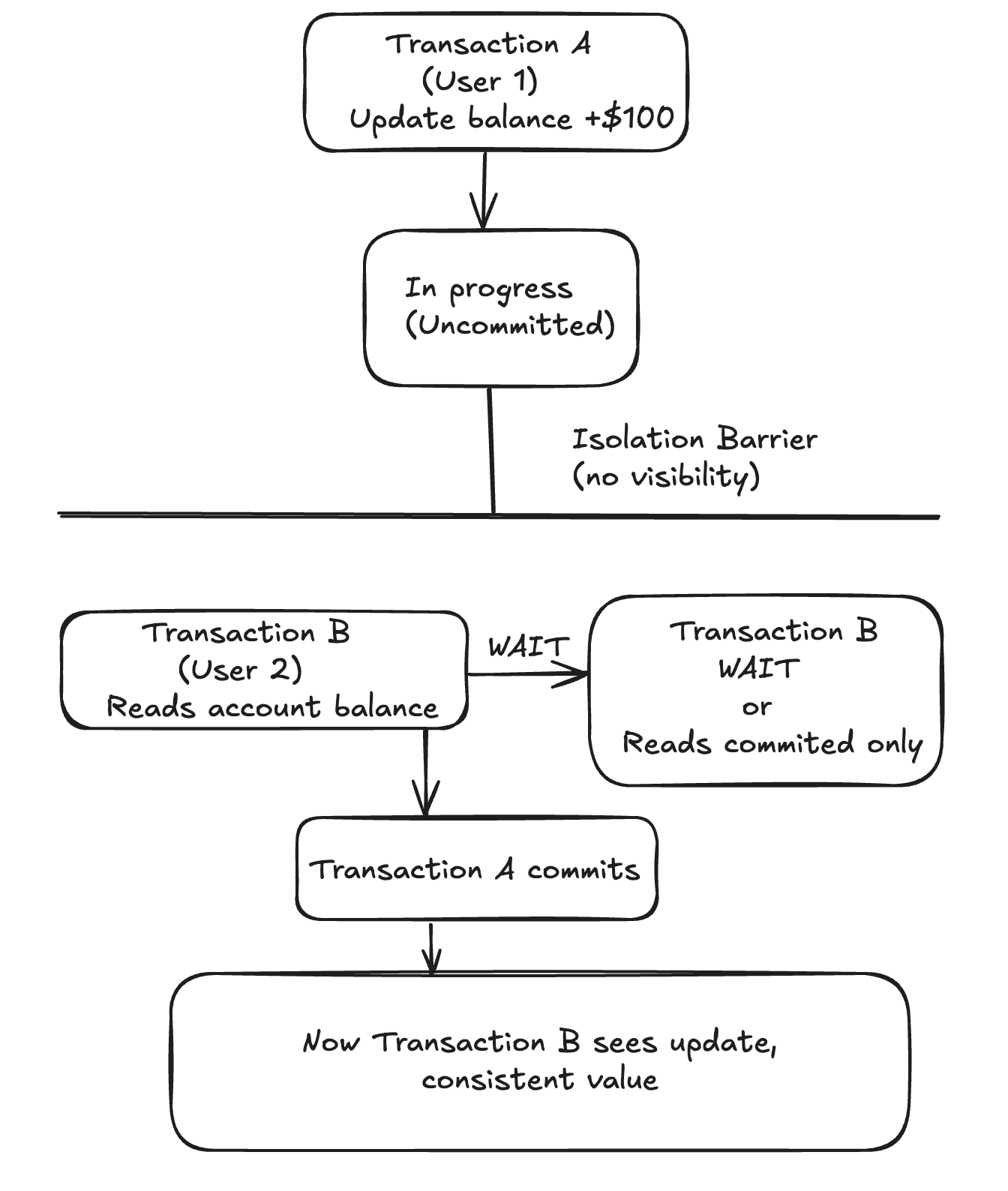
Isolation #
L’isolement signifie que les transactions concurrentes n’interfèrent pas les unes avec les autres. Chaque transaction fonctionne de manière indépendante et les états intermédiaires ne sont pas visibles par les autres transactions. Cela permet d’éviter des problèmes tels que les « dirty reads », où une transaction lit les modifications non validées d’une autre transaction. Par exemple, si deux utilisateurs mettent à jour simultanément le solde d’un même compte, l’isolation garantit que chaque transaction est traitée de manière à ce qu’elle ne voie pas les modifications non validées de l’autre. Cela permet de maintenir la cohérence des données et d’éviter les anomalies.
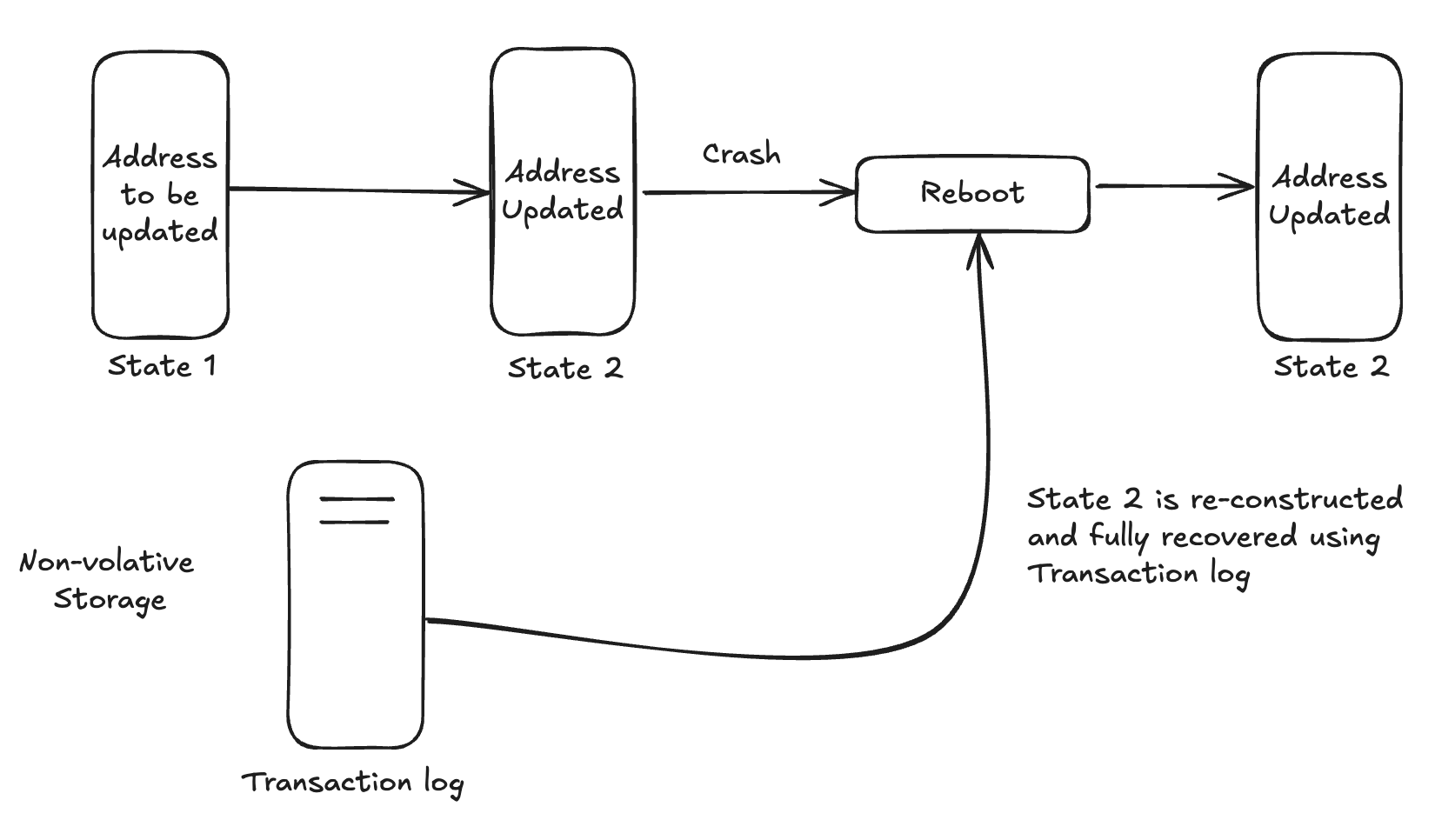
Durabilité #
La durabilité garantit qu’une fois qu’une transaction est validée, ses effets sont permanents, même en cas de défaillance du système. Cela signifie que les modifications apportées par la transaction sont enregistrées dans une mémoire non volatile. Par exemple, si vous mettez à jour l’adresse d’un client dans une base de données et que la transaction est validée, cette modification persistera même si le système tombe en panne immédiatement après. La durabilité garantit que les transactions validées ne sont pas perdues et que la base de données peut retrouver un état cohérent après une panne.
Combien de types ? #
Les bases de données peuvent être classées en quatre catégories :
Bases de données relationnelles (SGBDR) #
Utilisent des tables avec des schémas et des relations prédéfinis (par exemple, MySQL, PostgreSQL, SQL Server).
Bases de données NoSQL #
Bases de données qui traitent des données non structurées ou semi-structurées avec des schémas flexibles (par exemple, MongoDB, Cassandra).
Bases de données en mémoire #
Bases de données qui stockent les données dans la mémoire vive pour un accès rapide (par exemple, Redis). L’objectif principal est d’exploiter un ensemble limité de données avec une très faible latence.
Bases de données graphiques #
Base de données qui utilise des nœuds et des arêtes pour stocker des relations (par exemple, Neo4j).
Comment les bases de données interagissent-elles ? #
Les bases de données interagissent avec les applications et les utilisateurs par le biais de
Requêtes SQL #
Le langage SQL (Structured Query Language) est couramment utilisé pour récupérer ou modifier des données. Les opérations CRUD (Create, Read, Update, Delete) sont couramment utilisées pour interagir avec les bases de données. Ces opérations sont utilisées pour gérer les données dans une base de données.
Opérations CRUD #
Il existe quatre types d’opérations CRUD.
CreateReadUpdateDelete
Create #
CREATE est utilisée pour ajouter de nouvelles données à un tableau.
INSERT INTO entreprise.employes (nom, poste)
VALUES ('John Doe', 'Manager');
Read #
READ est utilisée pour extraire des données d’une table.
SELECT * FROM entreprise.employes;
Update #
UPDATE est utilisée pour modifier les données existantes dans une table.
UPDATE entreprise.employes
SET nom = 'Jane Doe'
WHERE id = 1;
Delete #
Delete est utilisée pour supprimer des données d’un tableau.
DELETE FROM entreprise.employes
WHERE id = 1;
APIs #
Les applications se connectent aux bases de données à l’aide d’API telles que JDBC (Java Database Connectivity) ou de services RESTful.
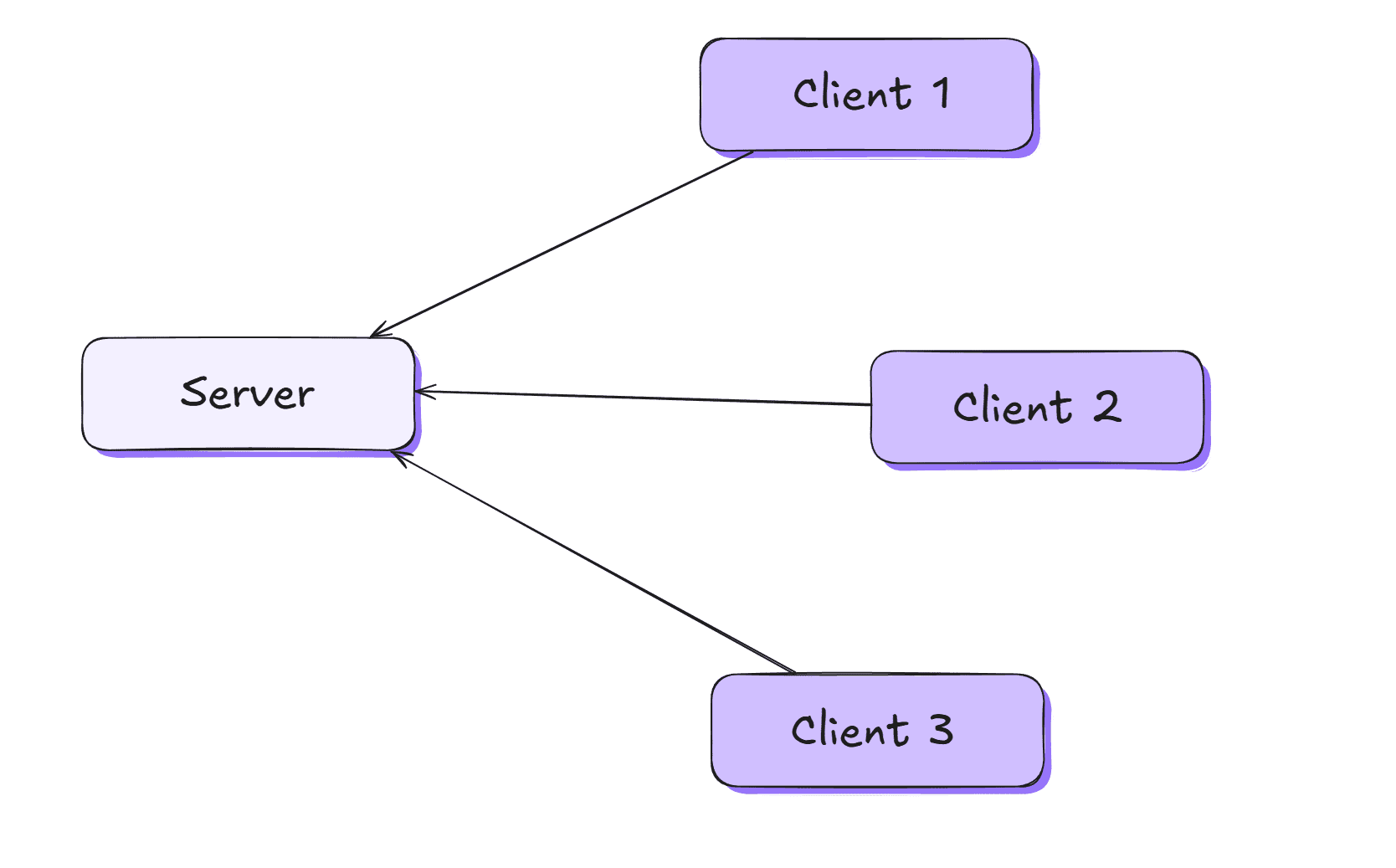
Architecture client-serveur #
Les bases de données fonctionnent sur un serveur et les clients (applications) demandent des données sur un réseau.
ORM (Object-Relational Mapping) #
Les développeurs utilisent des ORM (par exemple, Hibernate, SQLAlchemy) pour interagir avec les bases de données en utilisant des objets au lieu du langage SQL brut.
Réplication et sauvegarde #
La réplication consiste à copier les données d’un serveur de base de données (le primaire) vers un ou plusieurs serveurs répliques. Si le serveur primaire tombe en panne, les répliques peuvent prendre le relais (haute disponibilité). Les requêtes de lecture peuvent être envoyées aux répliques, tandis que les requêtes d’écriture restent sur le serveur primaire. Il peut également être utilisé pour conserver des copies à jour ailleurs (par exemple, dans une autre région).
La sauvegarde consiste à créer des snapshots ou des copies de l’ensemble de la base de données (données et parfois schéma) sur un support de stockage externe. Elle peut être utilisée pour conserver des données historiques, pour la migration des données et également si la base de données est corrompue ou perdue.