
Comment fonctionnent les bases de données ? #
Les bases de données fonctionnent à l’aide d’un Système de Gestion de Base de Données (SGBD), qui fournit des outils pour le stockage, la récupération et la manipulation des données.
Tables #
Une table est une structure de données utilisée pour stocker des informations sous un format structuré (lignes et colonnes).
Chaque ligne représente une entité de données, et chaque colonne définit un champ d’information spécifique. Les données contenues dans ces tables peuvent être consultées, modifiées, mises à jour et organisées via le langage SQL.
Chaque colonne possède un nom, un type de données et un ensemble de contraintes qui définissent les valeurs autorisées.
Clés #
Les clés sont l’un des éléments les plus importants d’une base de données relationnelle pour maintenir la relation entre les tables et elles permettent également d’identifier de manière unique les données d’une table. La clé primaire est une clé qui permet d’identifier de manière unique le tuple de la base de données. En revanche, la clé étrangère est une clé utilisée pour déterminer la relation entre les tables par le biais de la clé primaire d’une table, c’est-à-dire que la clé primaire d’une table agit comme une clé étrangère pour une autre table.
Qu’est-ce qu’une clé primaire ? #
La clé primaire est une clé qui permet d’identifier de manière unique le tuple de la base de données. Une clé primaire est utilisée pour s’assurer que les données d’une colonne spécifique sont uniques. Une colonne ne peut pas avoir de valeurs NULL. Il s’agit soit d’une colonne de table existante, soit d’une colonne spécifiquement générée par la base de données selon une séquence définie.
La clé primaire d’une table est facultative, mais il est déconseillé de l’omettre.
Qu’est-ce qu’une clé étrangère ? #
Une clé étrangère est une colonne ou un groupe de colonnes dans une table de base de données relationnelle qui fournit un lien entre les données de deux tables. Il s’agit d’une colonne (ou de plusieurs colonnes) qui fait référence à une colonne (le plus souvent la clé primaire) d’une autre table.
Schémas #
Un schéma est une structure logique qui définit la manière dont les données sont organisées (tables, relations, contraintes, index, etc.).
Une base de données peut contenir plusieurs schémas.
CREATE SCHEMA entreprise;
CREATE TABLE entreprise.employes (
id INT PRIMARY KEY,
nom VARCHAR(100),
poste VARCHAR(50)
);
Cardinalités #
Les cardinalités (ou multiplicités) indiquent le nombre d’instances d’une classe qui peuvent être associées à une instance d’une autre classe dans une relation (association).
Voici la liste des cardinalités les plus courantes et leur signification :
| Notation UML | Signification | Description |
|---|---|---|
0..1 |
Zéro ou un | Une instance peut être associée à aucune ou une seule autre instance. |
1 |
Exactement un | Il y a toujours exactement une instance associée. |
0..* ou * |
Zéro ou plusieurs | Il peut y avoir aucune, une ou plusieurs instances associées. |
1..* |
Une ou plusieurs | Il y a au moins une instance associée. |
n |
Exactement n | Il y a exactement n instances associées. |
0..n |
De zéro à n | Entre aucune et n instances associées. |
m..n |
De m à n | Au minimum m et au maximum n instances associées. |
Exemples concrets :
-
Une personne possède 0.. voitures* → une personne peut avoir aucune ou plusieurs voitures.
-
Une voiture appartient à 1 personne → chaque voiture a exactement un propriétaire.
-
Un cours est suivi par 1.. étudiants* → au moins un étudiant par cours.
Contraintes #
Une contrainte est une règle qui définit les valeurs et les types de données autorisés pour une table ou une colonne. Les contraintes sont utilisées pour garantir l’intégrité et la cohérence des données dans une base de données. En cas de violation entre la contrainte et l’action sur les données, l’action est interrompue.
Les contraintes suivantes sont couramment utilisées en SQL :
NOT NULL- Garantit qu’une colonne ne peut pas avoir une valeur NULLUNIQUE- Assure que toutes les valeurs d’une colonne sont différentes.PRIMARY KEY- Une combinaison de NOT NULL et UNIQUE. Identifie de manière unique chaque ligne d’une table.FOREIGN KEY- Empêche les actions qui détruiraient les liens entre les tables.CHECK- Assure que les valeurs d’une colonne satisfont à une condition spécifiqueDEFAULT- Définit une valeur par défaut pour une colonne si aucune valeur n’est spécifiée.CREATE INDEX- Utilisé pour créer et récupérer très rapidement des données dans la base de données.
Index #
Un index est une structure de données qui améliore la vitesse des opérations de récupération des données en fournissant des chemins d’accès rapides.
Un index peut être créé sur une ou plusieurs colonnes d’une table.
CREATE INDEX idx_employes_nom ON entreprise.employes (nom);
La création d’un index occupe de l’espace mémoire dans la base de données et, comme il est mis à jour à chaque modification de la table à laquelle il est rattaché, peut augmenter le temps de traitement du SGBDR lors de la saisie des données. Par conséquent, la création d’un index doit être justifiée et les colonnes auxquelles il se rapporte doivent être soigneusement choisies (de manière à minimiser les duplications). Ainsi, certains SGBDR créent automatiquement un index lorsqu’une clé primaire est définie.
Vues #
Une vue est une table virtuelle basée sur le résultat d’une requête. Elles permettent de simplifier les requêtes complexes et de fournir une vue simplifiée des données.
Les vues agissent comme une façade : Une vue peut être considérée comme une façade pour masquer la complexité d’un modèle de données.
-
Syntaxe de base : Utilisez
CREATE VIEWpour définir une vue à partir d’une requête complexe, souvent créée à partir de jointures multiples -
Règles courantes : Utiliser des requêtes les plus vastes possibles (éviter les restrictions
WHEREdans les vues, sauf si nécessaire) ; utiliser les alias pour les colonnes afin de faciliter les requêtes ultérieures et éviter les conflits de nommage. -
Les vues sont dynamiques : Lors de l’utilisation d’une vue, la requête originale est “rejouée”, les données récoltées sont donc bien celles qui existent dans les tables d’origine.
-
Les mises à jour sont interdites : les vues ne permettent pas l’ajout / modification / suppression de données.
CREATE VIEW v_employes AS
SELECT e.id, e.nom, e.poste
FROM entreprise.employes e;
Une vue s’utilise comme une table dans un SELECT :
SELECT firstname, lastname FROM employee;
Vous pouvez utiliser la vue comme un ensemble à part entière et donc l’inclure dans une jointure, une union, une intersection.
Une vue peut être supprimée :
DROP VIEW employee;
La suppression de la vue ne supprimera donc pas les données des tables ayant servi à la création de la vue.
Une vue peut être modifiée :
ALTER VIEW employee AS (new_query);
Transactions #
Garantir l’intégrité des données grâce aux propriétés ACID (atomicité, cohérence, isolation, durabilité).
Atomicité #
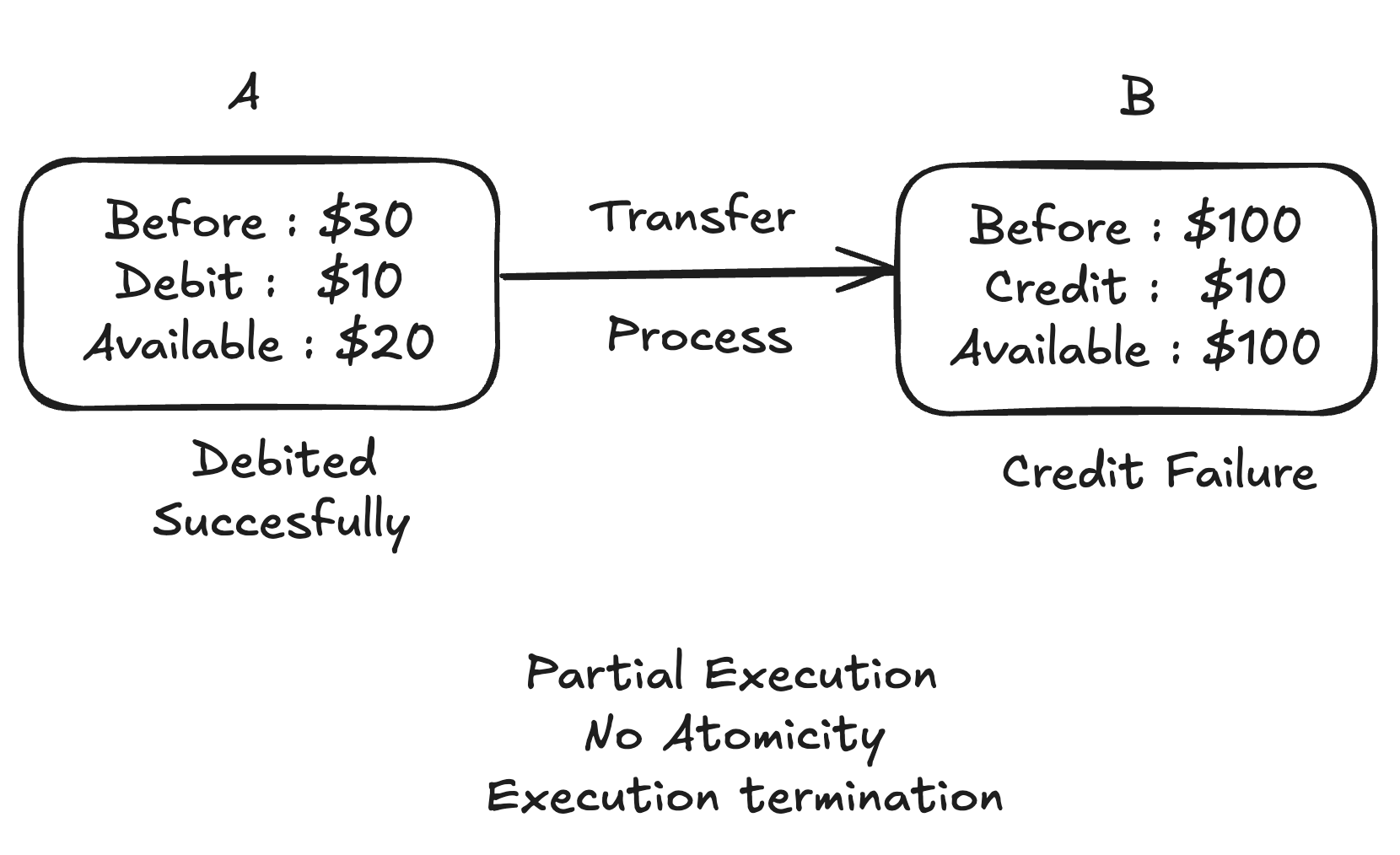
L’atomicité est le principe du tout ou rien. Lorsqu’une transaction est initiée, elle doit se terminer complètement ou ne pas se terminer du tout. Si une partie de la transaction échoue, la transaction entière échoue, la transaction entière est annulée, laissant la base de données inchangée. Par exemple, si vous transférez de l’argent entre des comptes bancaires, les opérations de débit et de crédit doivent réussir ensemble. Si l’une des parties échoue, aucune des deux opérations n’est appliquée, ce qui garantit que la base de données reste dans son état d’origine.
Cohérence #
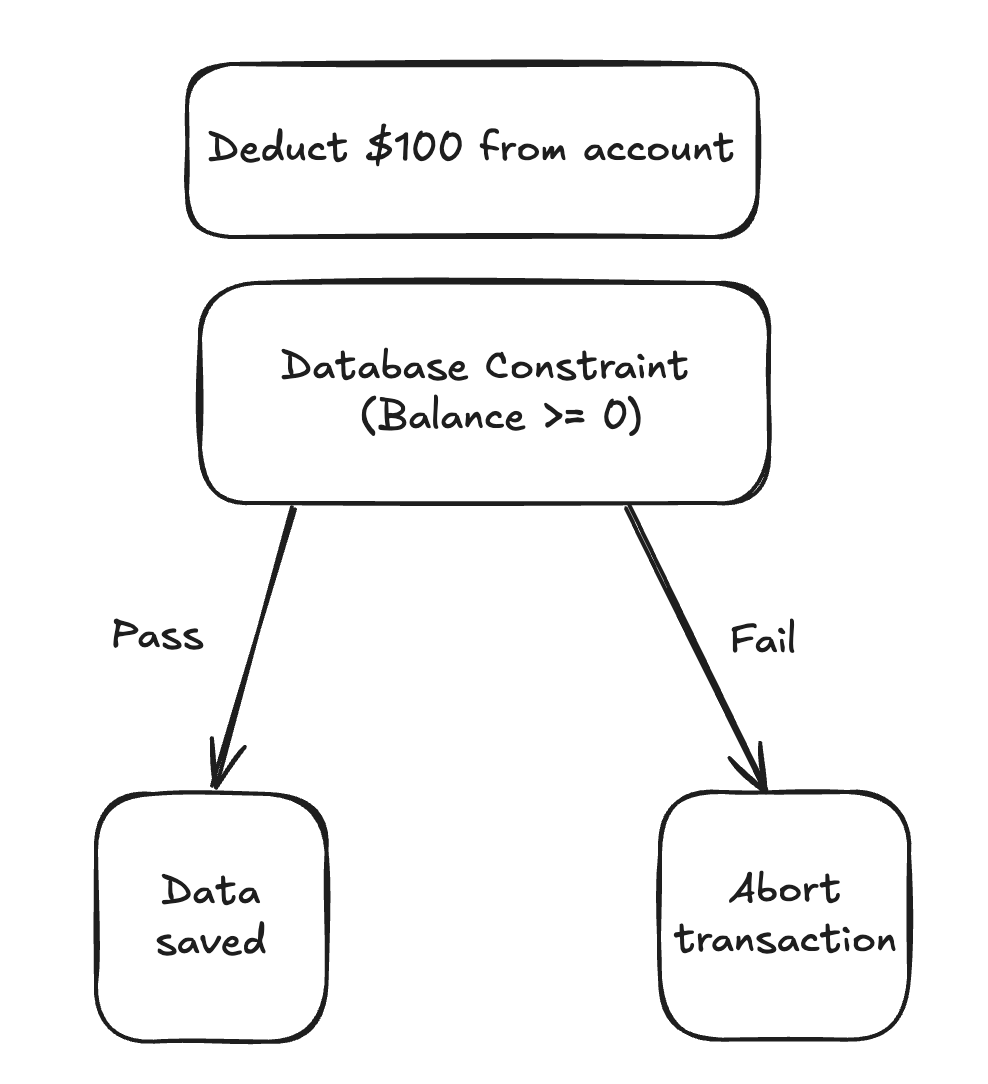
La cohérence garantit que la base de données reste dans un état valide avant et après la transaction. Cela signifie que toutes les contraintes d’intégrité des données sont maintenues tout au long de la transaction. Si une transaction enfreint une règle d’intégrité, elle ne sera pas validée. Par exemple, si vous avez une règle qui empêche les soldes négatifs sur les comptes bancaires, toute transaction tentant de mettre un compte à découvert sera annulée. Cela garantit que toutes les transactions conduisent la base de données d’un état cohérent à un autre, préservant ainsi l’exactitude des données.
Isolation #
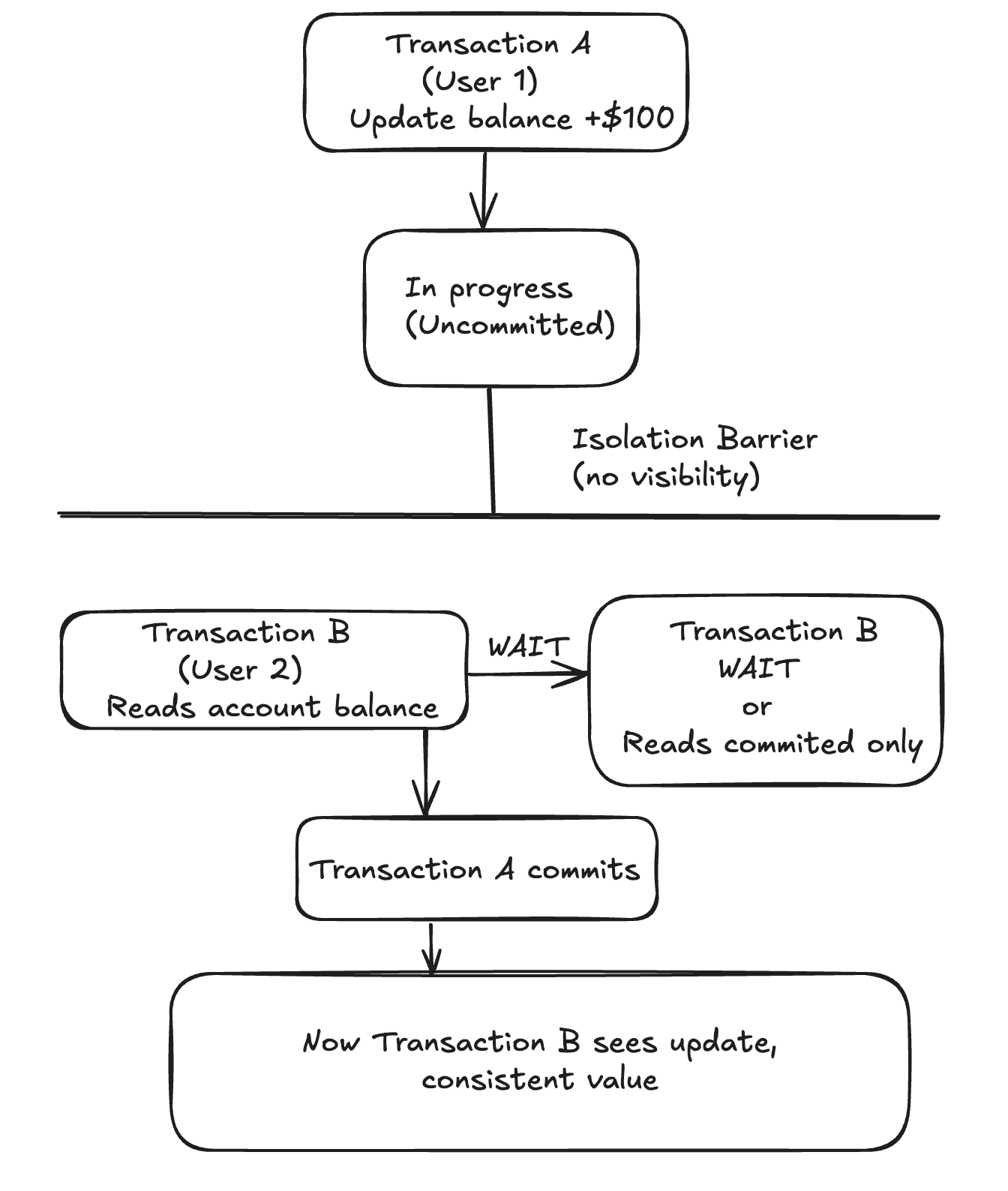
L’isolement signifie que les transactions concurrentes n’interfèrent pas les unes avec les autres. Chaque transaction fonctionne de manière indépendante et les états intermédiaires ne sont pas visibles par les autres transactions. Cela permet d’éviter des problèmes tels que les « dirty reads », où une transaction lit les modifications non validées d’une autre transaction. Par exemple, si deux utilisateurs mettent à jour simultanément le solde d’un même compte, l’isolation garantit que chaque transaction est traitée de manière à ce qu’elle ne voie pas les modifications non validées de l’autre. Cela permet de maintenir la cohérence des données et d’éviter les anomalies.
Durabilité #
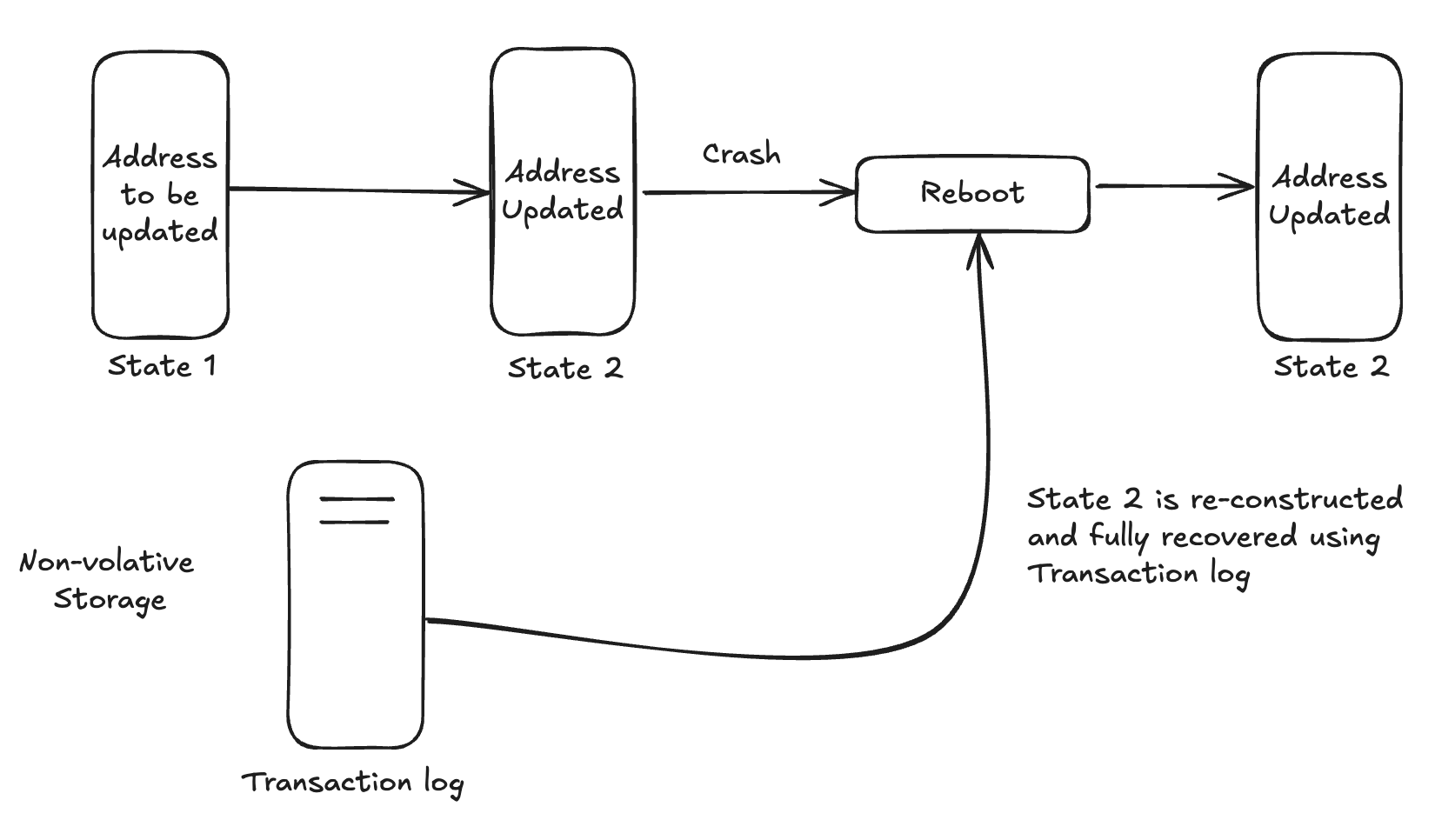
La durabilité garantit qu’une fois qu’une transaction est validée, ses effets sont permanents, même en cas de défaillance du système. Cela signifie que les modifications apportées par la transaction sont enregistrées dans une mémoire non volatile. Par exemple, si vous mettez à jour l’adresse d’un client dans une base de données et que la transaction est validée, cette modification persistera même si le système tombe en panne immédiatement après. La durabilité garantit que les transactions validées ne sont pas perdues et que la base de données peut retrouver un état cohérent après une panne.
Combien de types ? #
Les bases de données peuvent être classées en quatre catégories :
Bases de données relationnelles (SGBDR) #
Utilisent des tables avec des schémas et des relations prédéfinis (par exemple, MySQL, PostgreSQL, SQL Server).
Bases de données NoSQL #
Bases de données qui traitent des données non structurées ou semi-structurées avec des schémas flexibles (par exemple, MongoDB, Cassandra).
Bases de données en mémoire #
Bases de données qui stockent les données dans la mémoire vive pour un accès rapide (par exemple, Redis). L’objectif principal est d’exploiter un ensemble limité de données avec une très faible latence.
Bases de données graphiques #
Base de données qui utilise des nœuds et des arêtes pour stocker des relations (par exemple, Neo4j).
Comment les bases de données interagissent-elles ? #
Les bases de données interagissent avec les applications et les utilisateurs par le biais de
Requêtes SQL #
Le langage SQL (Structured Query Language) est couramment utilisé pour récupérer ou modifier des données. Les opérations CRUD (Create, Read, Update, Delete) sont couramment utilisées pour interagir avec les bases de données. Ces opérations sont utilisées pour gérer les données dans une base de données.
Types de données #
| Type | Description |
|---|---|
CHAR, VARCHAR |
Chaîne de caractères |
DATE, DATETIME, TIME, TIMESTAMP |
Dates et heures |
INT, FLOAT |
Nombres |
BLOB |
Données binaires (images, fichiers, etc.) |
JSON |
Données structurées |
POINT |
Coordonnées géographiques |
Commandes SQL de base #
La structure d’une requête SQL est composée de plusieurs commandes.
SELECT projection
FROM ensembles
WHERE conditions
GROUP BY critères_regroupement
HAVING condition_après_regroupement
ORDER BY critères_de_tri
LIMIT n;
La projection identifie les informations, séparées par une virgule, que l’on souhaite récupérer et lister. La projection se situe immédiatement après le SELECT et avant le FROM :
SELECT *
FROM student;
Cas spécifique “” : le caractère “” permet de définir toutes les colonnes de l’ensemble à “projeter”, en l’occurrence, dans l’exemple, toutes les colonnes de la table “employees”, cette requête est donc identique à :
SELECT id, lastname, firstname
FROM student;
Les “alias” de colonnes peuvent être utilisées pour différentes raison, la première est de rendre plus lisible un résultat :
SELECT lastname nom, firstname prenom
FROM student;
Le mot-clé “AS” peut être utilisé, mais n’est plus requis pour définir un alias, seul un espace entre la colonne de la projection et son alias suffit.
Les alias sont souvent utilisés pour les colonnes calculées dans la projection.
SELECT lastname, firstname, (salary * (1 - 40 / 100)) “net salary”
FROM student;
Il est recommandé d’utiliser les alias de colonnes lors de la création de vues.
Il est recommandé d’utiliser les alias dans les jointures pour éviter les ambiguïtés sur les noms de colonnes et/ou faciliter la lecture :
SELECT s.name, s.firstname, se.name
FROM student s JOIN service se ON s.service_id = se.id;
L’alias “s” identifie la table “student” ; l’alias “se” identifie la table “service”. On utilise généralement les initiales des tables en tant qu’alias. Une fois la table aliasée, il est obligatoire d’utiliser l’alias pour préfixer les colonnes.
WHERE condition #
Le filtrage des lignes est géré par la clause WHERE dans une requête.
WHERE sert à restreindre le nombre de lignes retournées, en fonction de
l’expression “booléenne” fournie.
Opérateurs :
=, >, <, >=, <=, <>, !=, AND, OR, XOR
Clauses :
LIKE, IN, BETWEEN, IS NULL
L’opérateur LIKE permet de déterminer l’appartenance d’une valeur à un ensemble de valeurs “approchantes” :
WHERE lastname LIKE 'd_boi%'; -- % = n’importe quelle chaîne après, _ = un caractère
Il est nécessaire de vérifier le comportement de l’opérateur LIKE en fonction du SGBD utilisé.
MySQL et MariaDB sont insensibles à la casse :
LIKE ‘DuPo%’ sera accepté pour toutes les formes de casse.
PostgreSQL étant sensible à la casse, il est nécessaire de lire la documentation pour obtenir le même résultat.
L’opérateur IN permet de déterminer l’appartenance d’une valeur à un
ensemble. On utilise souvent IN avec une sous-requête :
SELECT e.lastname, e.firstname
FROM employees e
WHERE e.service_id IN (SELECT id FROM services WHERE name
= ‘Accounting’ OR name = ‘Sales’);
L’opérateur BETWEEN permet de déterminer l’appartenance d’une valeur dans un intervalle. On utilise BETWEEN souvent avec les dates et les nombres :
SELECT e.lastname, e.firstname
FROM employees e
WHERE e.birthdate BETWEEN ‘1980-01-01’ AND ‘1990-12-31;
BETWEEN est inclusif, les bornes sont incluses dans le résultat
La valeur NULL est particulière en SQL. Il ne s’agit pas d’une valeur à
proprement parler, il est donc nécessaire d’utiliser d’autres opérateurs : IS [NOT] NULL
SELECT e.lastname, e.firstname WHERE salary IS NULL;
SELECT e.lastname, e.firstname WHERE salary IS NOT NULL;
Cette syntaxe est beaucoup utilisée dans les jointures externes.
GROUP BY condition #
La clause GROUP BY permet de regrouper des lignes selon un ou plusieurs
critères. Le GROUP BY est souvent utilisé avec les fonctions d’agrégations.
Le GROUP BY arrive toujours après le WHERE si appliqué :
SELECT
s.label,
AVG(e.note) AS Moyenne
FROM subject s
JOIN evaluation e ON s.id = e.subject_id
JOIN student su ON e.student_id = su.id
JOIN promo p ON su.promo_id = p.id
WHERE p.id = 1
GROUP BY s.id;
Le GROUP BY sert à regrouper les lignes par matière (subject).
Sans GROUP BY, AVG(e.note) calculerait la moyenne de toutes les notes de la promo, toutes matières confondues.
HAVING condition #
HAVING permet de filtrer les données après regroupement.
Exemple :
SELECT
s.label, p.label AS Promo, AVG(e.note) AS moyenne_par_promo
FROM subject s
JOIN evaluation e ON s.id = e.subject_id
JOIN student su ON e.student_id = su.id
JOIN promo p ON su.promo_id = p.id
GROUP BY p.id, s.id
HAVING moyenne_par_promo > 12;
HAVING moyenne_par_promo > 12 ne conserve que les groupes dont la moyenne est supérieure à 12.
ORDER BY condition #
ORDER BY permet de :
- Trier le résultat final selon une colonne ou plusieurs colonnes.
- Trier par ordre croissant (par défaut) ou par ordre décroissant (
DESC).
Exemple :
ORDER BY s.lastname, s.birthdate DESC;
La clause de tri permet de trier sur de multiples colonnes (présentes ou non dans la projection). La première colonne sera le premier ordre, les suivantes seront dépendantes de l’ordre immédiatement précédent.
Les lignes sont triées en premier lieu sur le nom, puis, les deux premières sont triées selon la date de naissance.
C’est optimisable via des index. On peut aussi définir la collation, la manière dont tu veux faire le tri. Exemple : Gestion de la distinction entre le e, le e accent aigue et grave.
Jointures #
Jointure interne #
Les jointures permettent de relier plusieurs ensembles de données selon leurs clés primaires et clés étrangères.
L’ancienne syntaxe définit avec le produit cartésien et une condition WHERE est la suivante :
SELECT s.lastname, s.firstname, p.label
FROM student s, promo p
WHERE s.promo_id = p.id; -- Reference la clé etrangere de student à la clé primaire de promo
Probleme : Il va passer par les centaines de promos et d’etudiants et il appliquera le WHERE…
D’abord produit cartesien puis elimination des lignes avec le WHERE.
La nouvelle syntaxe permet de définir les jointures avec la syntaxe suivante :
SELECT s.lastname, s.firstname, p.label
FROM promo p JOIN student s ON p.id = s.promo_id; -- Equivalent INNER JOIN, jointure interne.
JOIN ne renvoie que les correspondances entre les deux tables.
JOINcorrespond àINNER JOINpar défaut.
Exemple concret:
-- Lister les notes obtenues et les matieres
SELECT
e.note, s.label
FROM
subject s JOIN evaluation e ON s.id = e.subject_id; -- Référence la clé primaire de subject à la clé etrangere d'evaluation
Avec seulement la matiere “SQL”:
-- Lister les notes obtenues associé à la matiere "SQL"
SELECT
e.note, s.label
FROM
subject s JOIN evaluation e ON s.id = e.subject_id -- Référence la clé primaire de subject à la clé etrangere d'evaluation
WHERE
s.label = 'SQL'; -- Restraint à la matiere "SQL"
Il est également possible de créer des jointures multiples :
-- Lister les notes obtenues associé à la matiere "SQL"
SELECT
su.lastname, e.note, s.label
FROM
subject s
JOIN evaluation e ON s.id = e.subject_id -- Référence la clé primaire de subject à la clé etrangere d'evaluation
JOIN student su ON e.student_id = su.id -- Joint l'ensemble précédent (résultat d'une requete) à student en référencant la clé etrangere de evaluation à la clé primaire de student
WHERE
s.label = 'SQL'; -- Restraint à la matiere "SQL"
Il est conseillé de toujours commencer par la table/ensemble qui a le moins de lignes.
Jointure externe (LEFT JOIN / RIGHT JOIN) #
Les jointures externes permettent de conserver les lignes d’un ensemble, même lorsqu’il n’existe pas de correspondance dans l’autre ensemble.
Contrairement à la jointure interne (INNER JOIN), qui ne renvoie que les correspondances, une jointure externe affiche également les lignes « orphelines ».
LEFT JOIN (jointure externe gauche)
Le LEFT JOIN conserve toutes les lignes de la table de gauche, même si aucune correspondance n’existe dans la table de droite.
SELECT
e.note, s.label
FROM
subject s
LEFT JOIN evaluation e ON s.id = e.subject_id -- Conserver toutes les lignes de l'ensemble subject (LEFT)
WHERE
e.id IS NULL; -- Seulement les matieres dont les notes sont NULL
Le
OUTERest optionnelle, une jointure LEFT ou RIGHT est toujours par définition une jointure externe.
RIGHT JOIN (jointure externe droite)
Le RIGHT JOIN conserve toutes les lignes de la table de droite, même si aucune correspondance n’existe dans la table de gauche.
SELECT
e.note,
s.label AS Matiere
FROM
subject s
RIGHT JOIN evaluation e ON s.id = e.subject_id;
Exemple :
Lister toutes les évaluations (notes) même si la matière a été supprimée de la table subject :
SELECT
e.id, e.note, s.label AS Matiere
FROM
subject s
RIGHT JOIN evaluation e ON s.id = e.subject_id
WHERE
s.id IS NULL;
Union #
L’union est le concept ensembliste qui consiste à obtenir tous les éléments qui correspondent à la fois à l’ensemble A ou à l’ensemble B.
Concrètement, les ensembles mis en oeuvre doivent avoir le même nombre de colonnes, avec le même type et dans le même ordre.
SELECT col1, col2 col3 FROM ensemble1
UNION
SELECT col1, col2, col3 FROM ensemble2;
Par défaut, les lignes exactement identiques ne sont pas répétées dans le résultat.
Intersect #
L’intersection est le concept ensembliste qui consiste à récupérer les lignes communes entre plusieurs ensembles.
Concrètement, les ensembles mis en oeuvre doivent avoir le même nombre de colonnes, avec le même type et dans le même ordre.
SELECT col1, col2 col3 FROM ensemble1
INTERSECT
SELECT col1, col2, col3 FROM ensemble2;
Fenêtrage #
Les fonctions de fenêtrage ont été introduites en 2003 dans le langage SQL. Un peu à la manière des fonctions d’agrégation, elles opèrent des calculs sur l’ensemble retourné, mais à l’inverse de l’agrégation, les lignes sont conservées dans le résultat.
Le mot-clé OVER désignera la fonction de regroupement comme fonction de
“fenêtrage”.
L’exemple suivant illustre la manière d’utiliser une fonction comme fonction de fenêtrage :
SELECT
lastname,
firstname,
salary,
SUM(salary) OVER(ORDER BY lastname) salary_mass
FROM
employees;
On peut lire cette requête comme : effectue la somme des salaires sur l’ensemble des employés, ainsi que les noms, prénoms et salaires triés dans l’ordre de leur nom de famille.
Il est possible d’utiliser PARTITION BY dans la fonction de fenêtrage OVER afin d’opérer un regroupement sur une des colonnes.
SELECT
e.lastname,
e.firstname,
sv.name,
e.salary,
SUM(salary) OVER(PARTITION BY sv.id ORDER BY sv.name) s_salary_mass
FROM
service sv JOIN employees e ON sv.id = e.service_id;
Le résultat de la requête précédente donnera un résultat tel que le suivant :
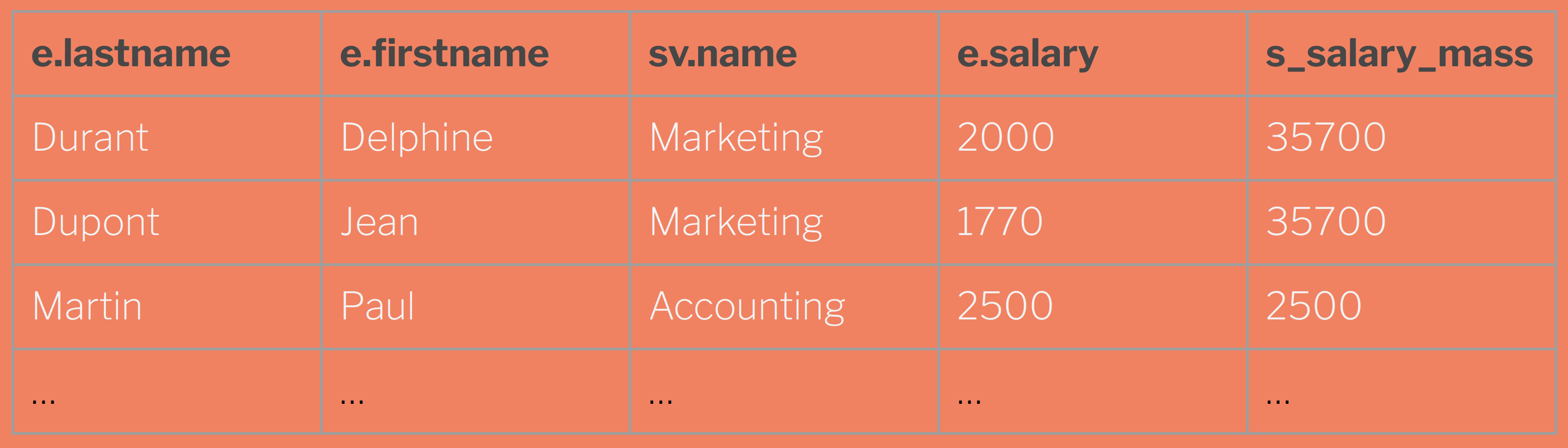
Ici, la fonction SUM avec fenêtrage sur s_salary_mass.
La fonction ROW_NUMBER() peut être utilisée pour afficher le numéro d’une ligne donnée. Utilisée conjointement avec un PARTITION BY la numérotation reprendra à 1 à chaque rupture.
SELECT service_id, lastname, ROW_NUMBER() OVER(ORDER BY service_id) num_row
FROM employees;
La fonction RANK() à l’inverse de ROW_NUMBER() qui donne des numéros
incrémentaux, fournit le rang (donc possiblement le même rang pour des
lignes différentes ayant la même valeur).
SELECT service_id, lastname, salary, RANK() OVER(PARTITION BY service_id ORDER BY salary) rank
FROM employees;
La fonction DENSE_RANK() identique à RANK() fournit le rang d’une valeur
mais au contraire de RANK() cette fonction ne sautera pas de rang en cas de valeurs identiques.
La fonction NTILE(slice_nb) permet d’afficher le numéro de la “tranche” de regroupement dans laquelle la ligne se situe.
La fonction LAG(col, distance), LEAD(col, distance) permettent d’afficher la colonne “col” à la distance “distance” soit en arrière (LAG) soit en avant (LEAD), ce qui peut être pratique pour comparer une valeur à une autre dans une requête.
Fonctions d’agrégations #
Les fonctions d’agrégations permettent de calculer des valeurs sur des colonnes.
Le langage SQL fournit 5 fonctions d’agrégations :
| Fonction | Description |
|---|---|
COUNT(*) |
Dénombre les lignes retournées par une requête SELECT |
SUM(expr) |
Cumule l’expression (expr) à partir des lignes retournées |
AVG(expr) |
Calcule la moyenne de de l’expression expr à partir des lignes retournées |
MAX(expr) |
Détermine la plus grande valeur expr à partir des lignes retournées |
MIN(expr) |
Détermine la plus petite valeur expr à partir des lignes |
Les fonctions dites d’agrégation ne retournent, dans une requête SQL simple, qu’une seule ligne. L’exemple suivant est donc incorrect :
SELECT e.lastname, COUNT(*) FROM employees e;
En effet, la machine ne saurait pas renvoyer (de manière simple), tous les noms de famille des salariés ainsi que le nombre de salariés ! Une erreur sera donc levée indiquant que vous ne pouvez pas utiliser une fonction d’agrégation dans ce contexte.
La fonction COUNT(expr) retourne donc le nombre de lignes impactées par
une requête SQL :
SELECT COUNT(*) nb_salaries FROM employees;
Cette requête va donc retourner le nombre de lignes total (*) de la table
employees.
SELECT COUNT(salary) nb_salaried_employees FROM employees;
Cette requête retournera le nombre de lignes de la table employees pour lesquelles la valeur de la colonne salary est NON NULLE.
SELECT COUNT(*) FROM employees WHERE service_id = 1; <= ?
La fonction AVG(expr) retourne la moyenne de l’expression définie (expr)
dépendant des lignes impactées :
SELECT AVG(salary) average_salary FROM employees;
Retourne donc la moyenne des salaires de la table employees.
SELECT AVG(salary) salary_mass FROM employees WHERE salary >= 2000;
Retourne la moyenne des salaires des employés gagnant plus de 2000 €.
La fonction MAX(expr) retourne la valeur maximale de l’expression définie
(expr) dépendant des lignes impactées :
SELECT MAX(salary) average_salary FROM employees;
Retourne le salaire le plus élevé de la table employees.
SELECT MAX(salary) salary_mass FROM employees WHERE salary < 2000;
Retourne le salaire maximum des employés gagnant moins de 2000 €.
La fonction MIN(expr) retourne la valeur minimale de l’expression définie (expr) dépendant des lignes impactées :
SELECT MIN(salary) average_salary FROM employees;
Retourne le salaire le moins élevé de la table employees.
SELECT MIN(salary) salary_mass FROM employees WHERE salary > 2000
AND service_id = 2;
Retourne le salaire minimum des employés gagnant plus de 2000 € dans le service dont le clé primaire vaut 2.
Transactions #
Garantir l’intégrité des données grâce aux propriétés ACID (atomicité, cohérence, isolation, durabilité).
Opérations CRUD #
Il existe quatre types d’opérations CRUD.
CreateReadUpdateDelete
Create #
CREATE est utilisée pour ajouter de nouvelles données à un tableau.
INSERT INTO entreprise.employes (nom, poste)
VALUES ('John Doe', 'Manager');
Le langage SQL permet d’insérer en une seule requête plusieurs lignes :
INSERT INTO employee VALUES (4, ‘Talut’, ‘Jean’, 1950), (5, ‘Lefort’, ‘Paul’,
2100), (6, ‘Dujardin’, ‘Martine’, 2500);
Les colonnes ont été omises car les données respectent le nombre et l’ordre des colonnes de la table, ainsi que les éventuelles contraintes et types définis.
Read #
READ est utilisée pour extraire des données d’une table.
SELECT * FROM entreprise.employes;
Update #
UPDATE est utilisée pour modifier les données existantes dans une table.
UPDATE entreprise.employes
SET nom = 'Jane Doe'
WHERE id = 1;
Attention : sans clause
WHEREdans une requête de mise à jour, c’est l’ensemble des lignes de la table qui est mis à jour.
L’utilisation de la clause WHERE est fortement recommandée.
Il est tout à fait possible d’utiliser, dans les requêtes SQL, des calculs. Par exemple, si on souhaite augmenter tous les salariés de 3%, on peut écrire la requête suivante :
UPDATE employee SET salary = salary * 1.03;
Delete #
Delete est utilisée pour supprimer des données d’un tableau.
DELETE FROM entreprise.employes
WHERE id = 1;
Attention, la requête DELETE devrait toujours être accompagnée d’une clause
WHEREpour éviter la suppression de toutes les lignes.
Considérations spéciales :
Une requête DELETE peut échouer si les contraintes d’intégrités
référentielles ne sont pas respectées.
Le mot-clé CASCADE peut être utilisé pour supprimer à la fois les lignes
d’une table ainsi que toutes celles qui sont référencées dans les autres tables.
Il est préférable d’utiliser une requête DELETE au sein d’une transaction.
Le mot-clé TRUNCATE peut aussi être utilisé pour supprimer des lignes dans une ou plusieurs tables.
TRUNCATE [CASCADE] table_name;
TRUNCATE vide complètement une table, il n’est pas possible d’y ajouter une clause WHERE, toutes les lignes seront supprimées. C’est l’équivalent de :
DELETE [CASCADE] FROM table_name;
TRUNCATE ne peut pas être restauré avec un ROLLBACK.
APIs #
Les applications se connectent aux bases de données à l’aide d’API telles que JDBC (Java Database Connectivity) ou de services RESTful.
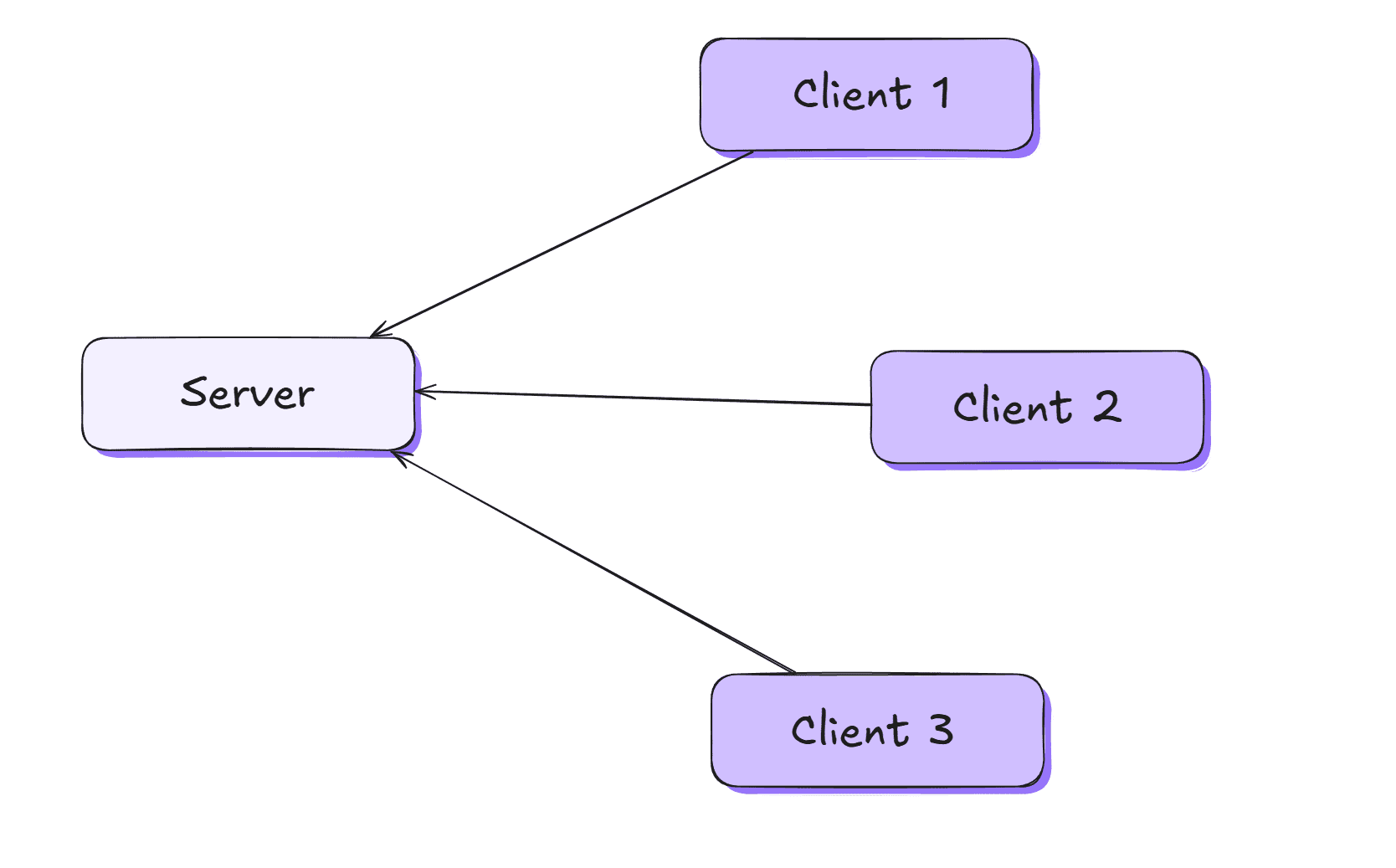
Architecture client-serveur #
Les bases de données fonctionnent sur un serveur et les clients (applications) demandent des données sur un réseau.
ORM (Object-Relational Mapping) #
Les développeurs utilisent des ORM (par exemple, Hibernate, SQLAlchemy) pour interagir avec les bases de données en utilisant des objets au lieu du langage SQL brut.
Réplication et sauvegarde #
La réplication consiste à copier les données d’un serveur de base de données (le primaire) vers un ou plusieurs serveurs répliques. Si le serveur primaire tombe en panne, les répliques peuvent prendre le relais (haute disponibilité). Les requêtes de lecture peuvent être envoyées aux répliques, tandis que les requêtes d’écriture restent sur le serveur primaire. Il peut également être utilisé pour conserver des copies à jour ailleurs (par exemple, dans une autre région).
La sauvegarde consiste à créer des snapshots ou des copies de l’ensemble de la base de données (données et parfois schéma) sur un support de stockage externe. Elle peut être utilisée pour conserver des données historiques, pour la migration des données et également si la base de données est corrompue ou perdue.
Exercice #
On nous demande :
- De lister les formations disponibles au catalogue Neolia
- De lister les formations avec leur thématique (i.e Informatique, Management),
- De lister le nombre de formations par thématique,
- De lister pour une formation donnée: les participants et e client payeur, • De lister le CA réalisé pour l’ensemble des actions de formation réalisées,
- De déterminer la part dans le CA payée par les OPCO,
- De déterminer le ca moyen (panier) des actions de formation réalisées par thématiques,
- De déterminer le nombre de jours vendus,
- De déterminer la marge des affaires, en globalisant par thématiques; la marge étant calculée selon la règle suivante : coût de la formation * nb_participants - nb-jours * tjr Formateur - nb-jours * frais_ fixe_location (80€)
- Montrer la part des financements publics et des financements privés
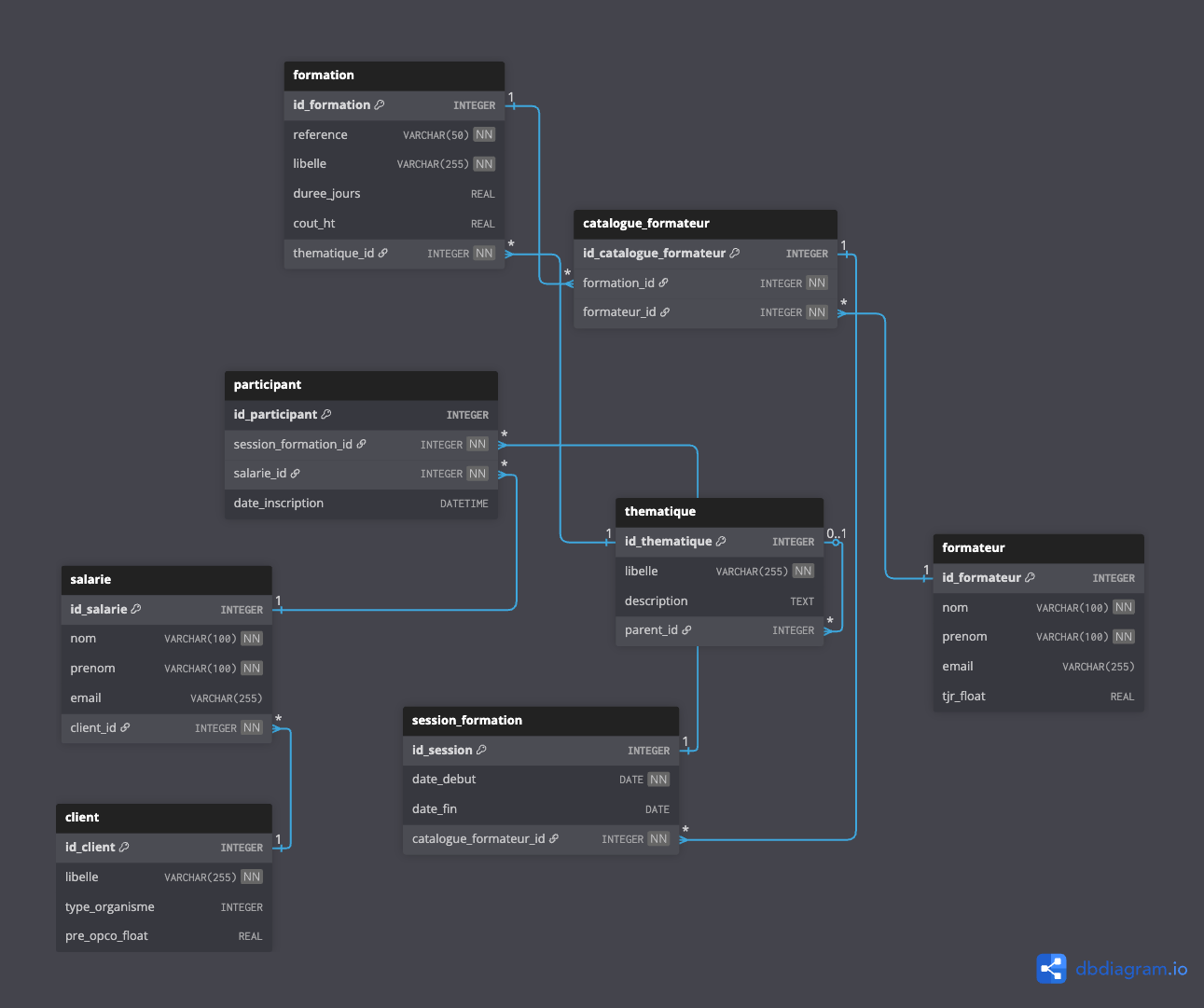
La base de données contient les informations suivantes :
Requêtes :
-- 1. Lister les formations disponibles au catalogue Neolia
SELECT
libelle
FROM
formation;
-- 2. Lister les formations avec leur thématique (i.e Informatique, Management)
SELECT
f.libelle, t.libelle
FROM
formation f
JOIN thematique t ON f.thematique_id = t.id_thematique;
-- 3. Lister le nombre de formations par thématique
SELECT
COUNT(f.id_formation) "Nombre formation", t.libelle "Thematiques"
FROM
formation f
JOIN thematique t ON f.thematique_id = t.id_thematique
GROUP BY
t.id_thematique;
-- 4. Lister pour une formation donnée : le nombre de participants et le client payeur
SELECT
s.id_session,
f.libelle nom_formation,
c.libelle client_payer,
COUNT(p.id_participant) nb_participants
FROM
participant p
JOIN salarie sa ON p.salarie_id = sa.id_salarie
JOIN client c ON sa.client_id = c.id_client
JOIN session_formation s ON p.session_formation_id = s.id_session
JOIN catalogue_formateur cf ON s.catalogue_formateur_id = cf.id_catalogue_formateur
JOIN formation f ON f.id_formation = cf.formation_id
WHERE
f.id_formation = 1
GROUP BY
s.id_session, f.libelle, c.libelle;
-- 5. Déterminer le CA réalisé pour l'ensemble des actions de formation réalisées
SELECT
SUM(ca_total) ca_global
FROM (
SELECT
f.cout_ht * COUNT(p.id_participant) ca_total
FROM
formation f
JOIN catalogue_formateur cf ON f.id_formation = cf.formation_id
JOIN session_formation sf ON cf.id_catalogue_formateur = sf.catalogue_formateur_id
JOIN participant p ON p.session_formation_id = sf.id_session
GROUP BY
f.id_formation
);
-- 6. Déterminer la part CA payée par les OPCO (clients privés avec pre_opco) --
SELECT
SUM(cout_ht * nb_participants) ca_opco
FROM (
SELECT
f.id_formation,
f.cout_ht AS cout_ht,
COUNT(p.id_participant) nb_participants
FROM
participant p
JOIN salarie s ON p.salarie_id = s.id_salarie
JOIN client c ON s.client_id = c.id_client
JOIN session_formation sf ON p.session_formation_id = sf.id_session
JOIN catalogue_formateur cf ON sf.catalogue_formateur_id = cf.id_catalogue_formateur
JOIN formation f ON cf.formation_id = f.id_formation
WHERE
c.type_organisme = 1
AND c.pre_opco_float IS NOT NULL
GROUP BY
f.id_formation, f.cout_ht
);
-- 7. Déterminer le CA moyen (€/jour) des actions de formation réalisées par thématique
SELECT
t.libelle thematique,
SUM(sub.cout_ht * sub.nb_participants) / SUM(sub.duree_jours * sub.nb_participants) ca_moyen_par_jour
FROM (
SELECT
f.id_formation,
f.cout_ht,
f.duree_jours,
f.thematique_id,
COUNT(p.id_participant) nb_participants
FROM
participant p
JOIN session_formation s ON p.session_formation_id = s.id_session
JOIN catalogue_formateur cf ON s.catalogue_formateur_id = cf.id_catalogue_formateur
JOIN formation f ON f.id_formation = cf.formation_id
GROUP BY
f.id_formation, f.cout_ht, f.duree_jours, f.thematique_id
) sub
JOIN thematique t ON t.id_thematique = sub.thematique_id
GROUP BY
t.id_thematique, t.libelle;
-- 8. Determiner le nombre de jours vendus
SELECT
f.duree_jours * COUNT(p.id_participant) jours_vendus, s.id_session, f.libelle
FROM
participant p
JOIN session_formation s ON p.session_formation_id = s.id_session
JOIN catalogue_formateur cf ON cf.id_catalogue_formateur = s.catalogue_formateur_id
JOIN formation f ON f.id_formation = cf.formation_id
GROUP BY
s.id_session;
Conclusion #
Il est essentiel de prendre le temps de réfléchir avant de concevoir la structure de nos données. Nous devons déterminer comment organiser nos données de manière non redondante afin d’optimiser la base. Il est important d’expliciter les relations de dépendances avec les cardinalités pour clarifier les liens entre les différentes tables. La première étape consiste à identifier quelles sont les informations données et leur rôle dans le projet. Pour tester le système, nous pouvons procéder à la création d’un jeu d’essai avec l’IA, et faire de même avec les requêtes. Il faut ensuite vérifier les résultats fournis par l’IA pour s’assurer de leur exactitude. Enfin, il est nécessaire de comprendre les noms des colonnes qui vont être retournées afin de manipuler correctement les données.